J’ai récemment été confronté à un problème très délicat. Un de mes proches animait un blog professionnel qui a été effacé à la suite d’une attaque d’un pirate informatique sur le serveur mutualisé qui l’hébergeait. Hors le site web en question avait accumulé un nombre de contenus spécialisés et reconnus depuis plusieurs années en affichant un volume de trafic important, mais celui-ci ne disposait malheureusement pas de sauvegarde automatique récente.
Même si l’on peut se demander comment un hébergeur puisse se faire pirater ses serveurs de la sorte et sans proposer de réplication ou autre forme de récupération des données, il faut aller de l’avant et essayer de trouver des solutions !
Je vais donc vous exposer la méthode que j’ai utilisée pour récupérer, au moins partiellement le site web.
1. Vérifier les éléments à notre disposition en local
J’ai d’abord recherché tous les éléments qui étaient à notre disposition sur des ordinateurs locaux. En l’occurrence, s’agissant d’un blog sous WordPress, j’ai pu récupérer le thème qui avait été conçu sur mesure à l’époque. C’est déjà pas mal pour commencer, cela nous fait le contenant !
Il est bon de voir également si des sauvegardes ont été faites, ou si l’on retrouve des textes ou des photos. Dans notre cas, nous n’avions ni sauvegarde, ni contenus textuels ou médias.
Néanmoins, j’ai pu commencer par réinstaller la dernière version de WordPress sur un serveur avec le thème sur-mesure.
2. Retrouver ses contenus sur le web
Une fois WordPress réinstallé et son premier article générique affiché, il nous reste à le remplir à nouveau avec les contenus originaux.
A partir de là, il n’y a pas une méthode unique car cela va dépendre de différents facteurs, mais je vous en livre 2 :
a. Examiner les pages en cache sur Google ou sur d’autres moteurs de recherche :
Si la perte de données est très fraîche quelques jours, il est généralement possible de récupérer au moins les contenus textuels : Il suffit d’effectuer une recherche du type « site:monsite.fr » qui va lister toutes les pages indexée de votre site et de cliquer en-dessous de chaque résultat sur le petit triangle vert. Là un petit menu propose un lien « En cache » qui va vous mener vers la page en question stockée chez Google. Vous pouvez ensuite choisir entre la version normale ou la version texte seulement sans style.

b. Naviguer chez les archiveurs du web :
Dans notre cas, le site était resté durant plus de 2 mois sans aucune action donc Google avait tout simplement désindexé entièrement le site et il n’y avait plus aucune page en cache.
Je me suis donc rendu sur le site archive.org. Ce site scrute un grand nombre de sites web, et archive leurs contenus dans sa propre base de données. Dans, notre cas, s’agissant d’un blog reconnu et relativement ancien, nous avons pu retrouver un grand nombre de page et d’article. Principalement les textes et parfois quelques photos !
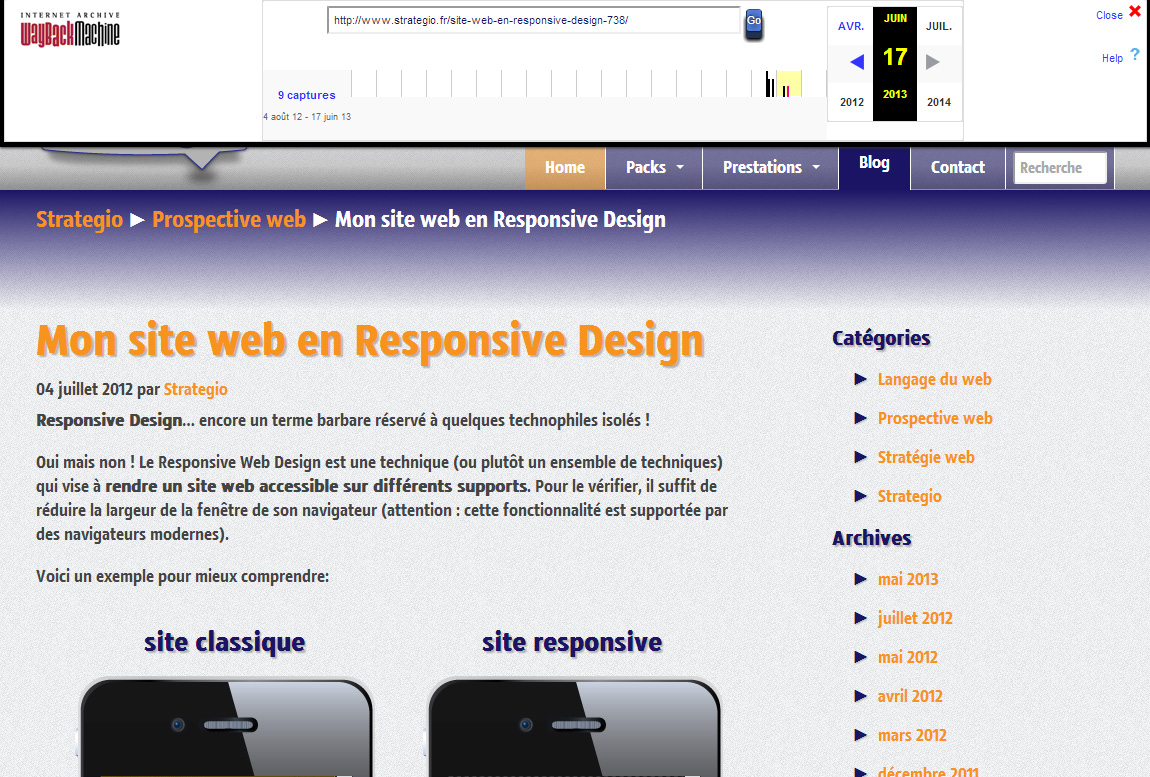
Il existe quelques autres sites d’archives, mais celui-ci me paraît le plus complet. En tous cas, je n’ai pas retrouvé de contenus de notre blog sur d’autre de ces sites.
Autre avantage avec archive.org, c’est qu’il peut archiver une même page a différentes dates ce qui permet également de retrouver des modifications. Je vous invite d’ailleurs a redécouvrir certains gros sites dans leur état d’époque, quelques exemples :
- version beta de Google le 2 décembre 1998
- site web de l’Elysée le 12 février 1998
- site du journal « Le Monde » en octobre 1996
3. Réintégrer les contenus sur le site
Nous avons donc récupéré quasiment tous les contenus textuels à part quelques articles très récents. Mais c’est là que les choses difficiles commencent…
Pour chaque article ou chaque page, il nous faut copier le contenu texte, mais également copier les images (un simple clic droit et « enregistrer sous » suffit) et les recharger sur le blog .
Attention, le maillage interne et tous les liens présents sur archive.org (dont les images) renvoient vers d’autre pages d’archives de ce même site.
Par exemple, concernant le site strategio.fr, on retrouve des liens de la forme https://web.archive.org/web/20130617131504im_/http:/www.strategio.fr/wp-content/uploads/2012/07/site-web-responsive-design.jpg pour les images et https://web.archive.org/web/20130617131504/http://www.strategio.fr/categorie/langage-du-web/ pour les liens internes.
Concernant les liens d’images, je pense que le plus simple est de les supprimer et de les réimplanter à l’aide de la page d’édition du CMS (WordPress). En effet, lors du rechargement de l’image, celle-ci va être implantée dans un répertoire différent du fait de la date. Vous me direz qu’il est possible de recréer la structure de fichiers sur le serveur. Oui, mais je vous le déconseille car lors du chargement d’une image WordPress génère automatiquement d’autres tailles d’images pour les vignettes par exemple et enregistre l’image en question dans la base de données pour pouvoir la retrouver par la suite… à vous de voir selon le volume et l’utilisation que vous faites de ces images.
Pour les liens internes ou externes, il s’agit d’un travail de fourmi. il faut retirer toute la première partie du lien https://web.archive.org/web/20130617131504/. Comme les numéros de date changent souvent, on ne peux pas faire un simple rechercher/remplacer… Enfin si !
Pour coder, j’utilise un éditeur de texte qui se nomme Sublime Text (un vrai couteau Suisse pour développeurs). Ce dernier permet de faire des recherches par expressions régulières. Sans rentrer dans les détails, il s’agit d’une méthode universelle pour cibler et modifier des portions de chaînes de caractères.
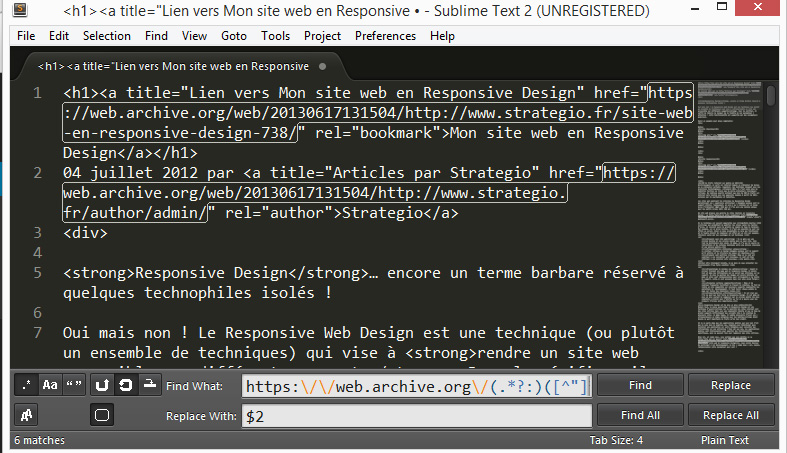
L’expression régulière que j’ai utilisée est la suivante :
https:\/\/web.archive.org\/(.*?:)([^"]*)
Dans Sublime Text, faire CTRL+H. Dans le premier champ (Find What), placer l’expression régulière ci-dessus et dans l’autre champ (Replace With) écrire $2 ce qui signifie que l’on remplace tout ce que l’on trouve par le second élément capturé. Vérifiez également que la recherche par expression régulière est bien activée avec le « petit point et l’étoile » sous forme de bouton à gauche.
Bien sûr, tout cela doit être appliqué sur le code HTML, donc voici comment j’ai procédé :
- sur la page archive.org, sélectionner le contenu avec la souris et le copier (CTRL+C). Attention à ne pas prendre en-tête, barre latérale et pied de page.
- sur WordPress, créer un nouvel article (ou page), et faire un coller direct (CTRL+V) dans l’onglet « Visuel »
- cliquer sur l’autre onglet « Texte », sélectionner tout le texte (CTRL+A) et couper (CTRL+X)
- coller tout ce qui vient d’être coupé sur Sublime Text
- appliquer les modifications en cliquant sur « Replace All » (après avoir fait les paramétrages vus plus haut)
- re-sélectionner tout le texte (CTRL+A), couper (CTRL+X) et coller le tout sur l’onglet « Texte » de WordPress
Ensuite il suffit de saisir les autres informations manuellement comme le titre, les catégories et/ou tags, etc. Concernant le permalien de l’article, tout va dépendre du paramétrage de WordPress, différents cas sont possibles, mais il faut essayer de respecter le lien tel qu’il existait auparavant. Si toutefois vous utilisiez des ID dans vos permaliens, cela poserait un problème pour le maillage interne, mais il s’agit là d’un problème secondaire para rapport à la problématique initiale.
N’oubliez pas, une fois les différents articles et pages recréés de paramétrer vos menus et widgets en conséquence.
Je me suis également offert le luxe de récupérer les commentaires des articles car ceux-ci étaient très étoffés et contribuaient de manière importante aux contenus globaux du site. Mais on peut considérer cette démarche comme optionnelle.
4. Bilan de l’opération
L’opération de sauvetage du blog ma demandé une bonne journée de travail avec en plus quelques modifications a apporter sur le thème qui n’était plus compatible avec la dernière version de WordPress. Le blog comportait entre 50 et 100 articles donc cela reste faisable de manière semi-automatique. Pour un site qui comporterait plusieurs centaines de pages voire plusieurs millier, je pense qu’il faudrait automatiser tout cela avec un petit script maison.
En terme de référencement, le résultat est très positif. Avant l’attaque, le site était premier incontesté sur sa thématique. Après avoir disparu du web durant 2 ou 3 mois et ayant été désindexé par Google, nous n’avions aucune garantie quant à la réindexation et au positionnement du site. Quelques jours après la republication des articles, Google a fait son travail d’indexation et le site s’est immédiatement repositionné en tête de classement. Un point intéressant pour les SEO qui donnera peut-être des idées à certains pour recycler des sites disparus ;) sur certaines thématiques…
Laissez un petit commentaire si cette méthode vous a permis de sauver ce qui pouvait l’être !